When I first started this PhD program, I had a desire to keep all my references and papers in my computer. Better to search them. Better to keep them in one place. No dog-eared corners and ripped notebook paper in 3-ring binders. I wanted to minimize the stacks of paper that I knew would accumulate on the floor of my office. I wanted to preempt the piles that I’ve got a reputation for creating.
The fact that this was a pipe dream is fodder for another discussion at another time. I want to talk about how I am managing the documents I do have in electronic form.
One of the ways I devised to attack the problem of the piles was to locate and continue to use a reference manager for my electronic files (mostly PDFs). There were a few to choose from so I needed to make a decision. I decided I’d choose based on 1) open formats, 2) documentation, and an 3) open development model (open source). After looking through RefWorks, vanilla BibTeX files, ProCite, EndNote, Reference Manager (the application) and BibDesk, I chose BibDesk.
BibDesk (screenshots) wins because of these:
- Open data format: BibDesk is a Mac app built to manage BibTeX files. BibTeX is an open format designed to be easily edited and easily moved from platform to platform (it’s plaintext). It has been developed by many eyes over many years and seems to be one of the most robust and flexible formats available for keeping track of bibliographic records.
- Documentation: Being as old as it is, BibTeX has a great number of well documented use cases. Many of the people who use BibTeX have documented their different situations online, where I can find them through basic web search. This is a very big deal – as I can be confident that whatever it is I’m trying to do with the software, I’m probably not the first. And BibDesk itself is documented pretty well too.
- Open source code: The codebase for BibDesk is open and available for download, inspection, and editing (if you are so inclined). I can trust that the format and application with which I’m choosing to manage my papers and references will not go away tomorrow. The company that owns the application cannot decide tomorrow that I need to pay to upgrade or that a particularly favorite feature is no longer necessary (and therefore no longer available). The fact that BibDesk also happens to be under quite active development is an added bonus. It is not uncommon when, if I’ve noticed something with BibDesk that I find annoying or less-than-polished, upon upgrading, it is improved or fixed outright. This continual improvement and attention to detail is a good thing and cannot be overstated as a matter of instilling confidence in a software selection.
As an added piece of the BibTeX/BibDesk solution I chose Subversion for version control. Version control protects me from errors/deletion of my own doing as well as those caused by “accidents” like power-failures or bad disk drives, etc. Subversion works well with the rest of this system because the entire BibTeX file is simple text. It also allows me seamless syncronization between different computers (home and school) and I can be sure I always have the most recent updates (read: PDFs I’ve already found once) available to me, no matter where I happen to be studying/working.
Additionally, by having my subversion repository “in the sky” (my hosting provider) I’ve got yet a third place where the data lives, making it even less likely that I’ll lose it in a fat-fingered accident or because someone has stolen my laptop.
I’ve collected the steps for my personal SVN/BibDesk/BibTeX solution below. I share them here since, when researching this on my own, nobody seemed to have this setup documented in one place.
Downloading and Installing BibDesk
This is one of the most straightforward steps. You can get BibDesk from the project’s homepage. Once the dmg is mounted, simply drag BibDesk to your Applications directory.
Configuring BibDesk
I made a couple choices as to how I wanted BibDesk to work – and I share them here because the choices work well with the plans I had for Subversion.
I want BibDesk to manage my PDFs like iTunes manages music files. I do not want to have to name all the PDFs and make sure they’re in the right place and constantly worry about whether I’ve saved it correctly. I want to tell the reference manager that I’ve got a reference, and I’ve got the electronic version of that reference, and please link them together. But I also want to be able to dig into that file tree later and browse to a well-named PDF so I can send it to a friend or colleague.
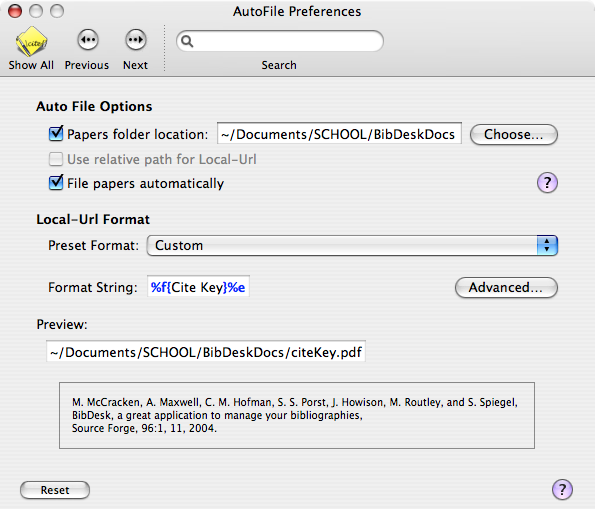
BibDesk does this through two features – the CiteKey, and AutoFile. Both are found in the BibDesk preferences panel.
CiteKey is where you define your unique identifier for each entry across your library of references.
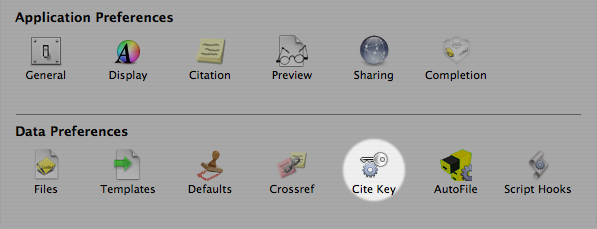
I have chosen “First Author, Year, First 20 Characters of Title” as my convention. This gives the “Format String” the value of “%a1%Y%t20”. Many others before me have chosen different format strings, but this combination seems to be a good balance between regular citation convention and the need to remain useful when simply browsing the file tree.
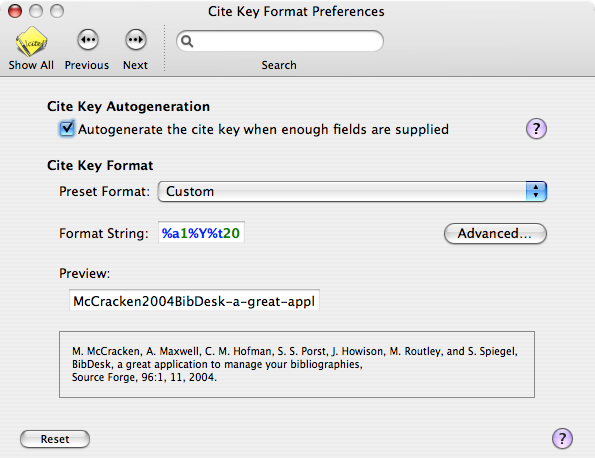
The CiteKey determines how the references are kept unique within the BibTeX file. I take this an extra step and keep that same format as the unique key for naming the attached PDFs as well. This is where the AutoFile preferences come into play.
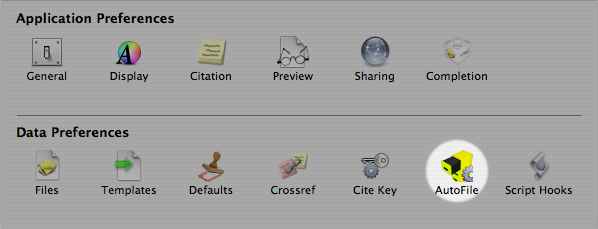
I tell BibDesk to store my files in a set directory. I tell BibDesk to file my papers automatically (like iTunes). And I tell BibDesk to use the same format I had just defined for the CiteKey. The format string for this is “%f{Cite Key}%e”. The %e on the end tells BibDesk to use the file extension usually associated with that type of file (almost always .pdf for me).
Update: Additionally, consider checking the second box (relative path for local-urls) if you’re using subversion to manage your BibTeX file from multiple machines with different full paths. I missed this myself, as my machines have consistent user accounts (and therefore, full paths).
And that’s it for the BibDesk setup. BibDesk should now store my references automatically as I find them and save them in the GUI. When I want to get back to a linked PDF from within BibDesk, I can simply double-click on it, and the linked file will open in my PDF viewer. No more digging around for lost files. I could also go browse the file tree where I told BibDesk to store my files – and they’ll be there named well and easy to scroll through.
Of course, BibDesk itself has keywords (tagging), annotation, and search – so it’s easy to find the reference you’re looking for from within the app in the first place as well.
Subversion
Subversion is a version control system that allows you to track changes across a file system. Read more about it here and here.
The system works as follows… There is a repository that holds your files. This repository could live on your computer or somewhere else. Mine lives “in the sky” at my hosting provider and is a full copy of all my SCHOOL files. When you work with subversion, you’re actually always interacting with a “working copy” on your local machine. When you are ready to save your changes to the version control system, you “commit” your changes back to the repository. If you are on a different machine with a different working copy of the same repository (this can be used by multiple people as well…), you simply have to resync that working copy, and it will download all the changes made to the repository in the sky. Magical stuff, no? Multiple computers, in sync, and no hard thinking necessary.
My BibDesk files are only a part of a greater collection of documents that I have under version control – but you can see how they live under the SCHOOL folder here.
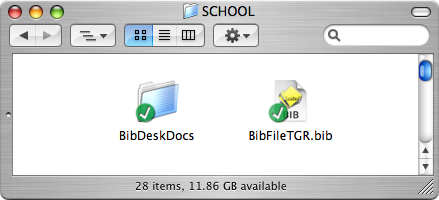
My BibTeX file (“BibFileTGR.bib”) lives right alongside the “BibDeskDocs” directory that I specified above in the AutoFile preferences panel. All my collected PDFs live in that BibDeskDocs directory. When things change in the BibTeX file or in the Docs directory, I commit the changes to the subversion repository and never think about it again. They’re safe. I’ve got a remote backup, and a full history of changes, built-in.
Configuring Subversion
Installing Subversion and getting it functional on your system is beyond the scope of this document, but please take the time to consider using it. It’s an integral part of what makes this system so powerful.
Quite a few hosting companies provide svn space. My own stuff is hosted at TextDrive.
Here are some of the Knowledge Base articles at TextDrive about getting your subversion up and running. If they’re not exactly the same as your setup, they shouldn’t be too far off. Again, the power of plaintext configuration and open source documentation.
Feedback
I’d love to hear from others who are using something like this for their own reference management. Do you have anything to add? Anything I left out?
I had used version control for my software projects for a while, but definitely had a moment when everything clicked for me when I realized my BibTeX was just plaintext as well and would fit very nicely within my existing setup.
I won’t be locked into a vendor – or an upgrade cycle – or an opaque “corruption” of my database file. I’ll even be protected against my own fat fingers, since I have the ability to go “back in time” through my versions after a bad save or deleted reference (oops).
Presumably, I can continue to cultivate and build my reference library for many years and never have to worry about it disappearing or getting corrupted.
Tags: bibdesk - bibtex - PIM - subversion